Yet another COVID-19 cases public API - implemented with Micronaut, Google Cloud Run, Elastic Search and gitlab!
It is more than certain that the world has already enough APIs and web pages where you can check daily the progress of your country in terms of COVID-19 cases, deaths and other statistics. So this post is not about my API (even though is up there, and I am planning to keep it online, and you are more than welcome to use it or provide feedback).
This particular experiment it mostly an opportunity to code along and have fun with my good friend Stathis Souris who has contributed the Elastic Search part of the implementation and practically was the reason I picked up this idea after he _demo-ed me some months ago how he ingested our particular dataset to elastic search!
The API and how to use it
If you don't want to read further down, here is the API. It offers 3 basic calls,
- list all the available countries that we have data
- get results for a specific countru
- get the top 10 countries (cases/deaths)
Base URL: javapapo.eu/covid
List all the available countries, that you can pick results
1curl https://www.javapapo.eu/covid/countries
This will return a JSON, with all the countries that you can use, on the next call and receive resuls
Get totals for a specific country
1curl https://www.javapapo.eu/covid/countries/Greece
2curl https://www.javapapo.eu/covid/countries/United%20Kingdom
3curl https://www.javapapo.eu/covid/countries/United%20States
Get the top10 countries
1curl https://www.javapapo.eu/covid/top10
Where we get data from
We pull data from the John Hopkins School of engineering. The school is kind enough to maintain a Github repo where daily they upload data with the latest official results.
Every day, at about 6am (GMT) we have a very small java application, that is kicked using a Gitlab Scheduled Job, pulls the CSV file and after a small transformation it _ingests the data to a small Elastic Search instance on elastic cloud!

Overall solution
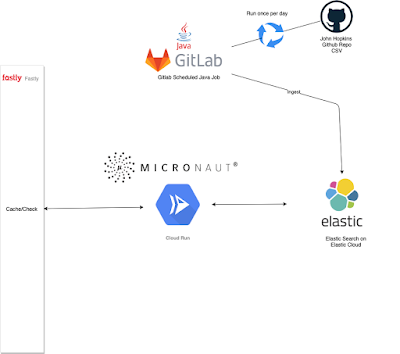
- As we have already elaborated, we run once per day, a plain Java service with Gradle, making use of Gitlab's Scheduled CI executors, that pulls the CSV file, and pushes data to a small instance on Elastic Cloud
- The main API is a small Micronaut Microservice, deployed on Google Cloud Run. It currently runs with 256 MB total memory and 1 CPU. The service uses the High Level Elastic Search Java Client and the relevant Micronaut Elastic Search Integration. It also makes use of local in memory caching with Caffeine (it is already bundled with the micronaut-cache module).
- The Google Cloud Run endpoint is _fronted by Fastly, in order to make use of Fastly's excellent web caching and related functionalities. It also acts as a guard to potential floods of request.